Neuro-Tech
[딥러닝101] 이미지로 시작하는 딥러닝 이해 4편: 모델 성능을 위한 레이블링과 데이터
들어가며
저번 시간에는 딥러닝 모델 학습에 필요한 레이블링 과정과, 이를 적용한 task 들에 대해 알아보았습니다. 이러한 task에는 앞서 살펴본 Classification, Object Detection, OCR 외에도 다양한 종류가 있는데요. 오늘은 다른 종류의 task에 대해서 알아보고, 데이터의 수량과 딥러닝 모델 간에 어떠한 관계가 있는지 탐구해 보도록 하겠습니다.
Dive in to tasks: 또 무엇이 있을까?
이번 시간에 살펴볼 task에는 대표적으로 다섯 가지 모델이 있습니다. 바로 Segmentation, GAN, Anomaly Segmentation, Anomaly Classification, 그리고 Rotation이죠. 특히 Segmentation, GAN, Anomaly Segmentation의 세 모델은 모두 아주 다른 역할을 하는 모델이지만, 레이블링 관점에서는 동일하기 때문에 한 번에 묶어서 설명이 가능합니다.
[1] Segmentation/GAN/Anomaly Segmentation
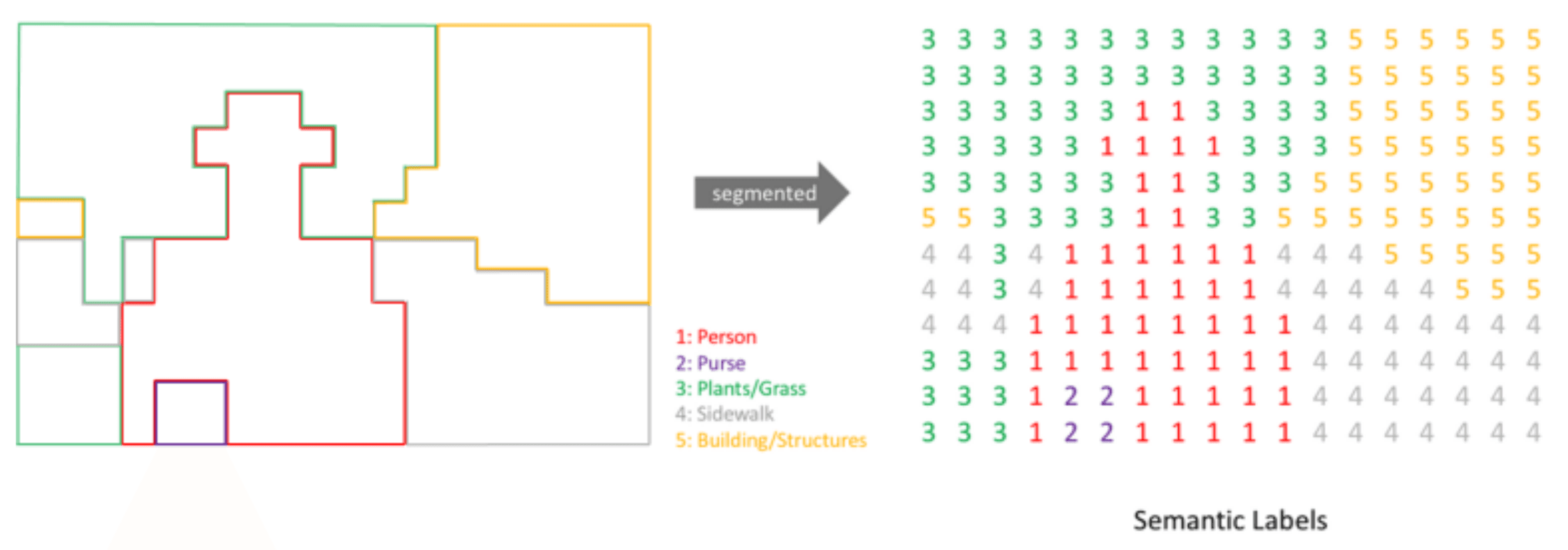
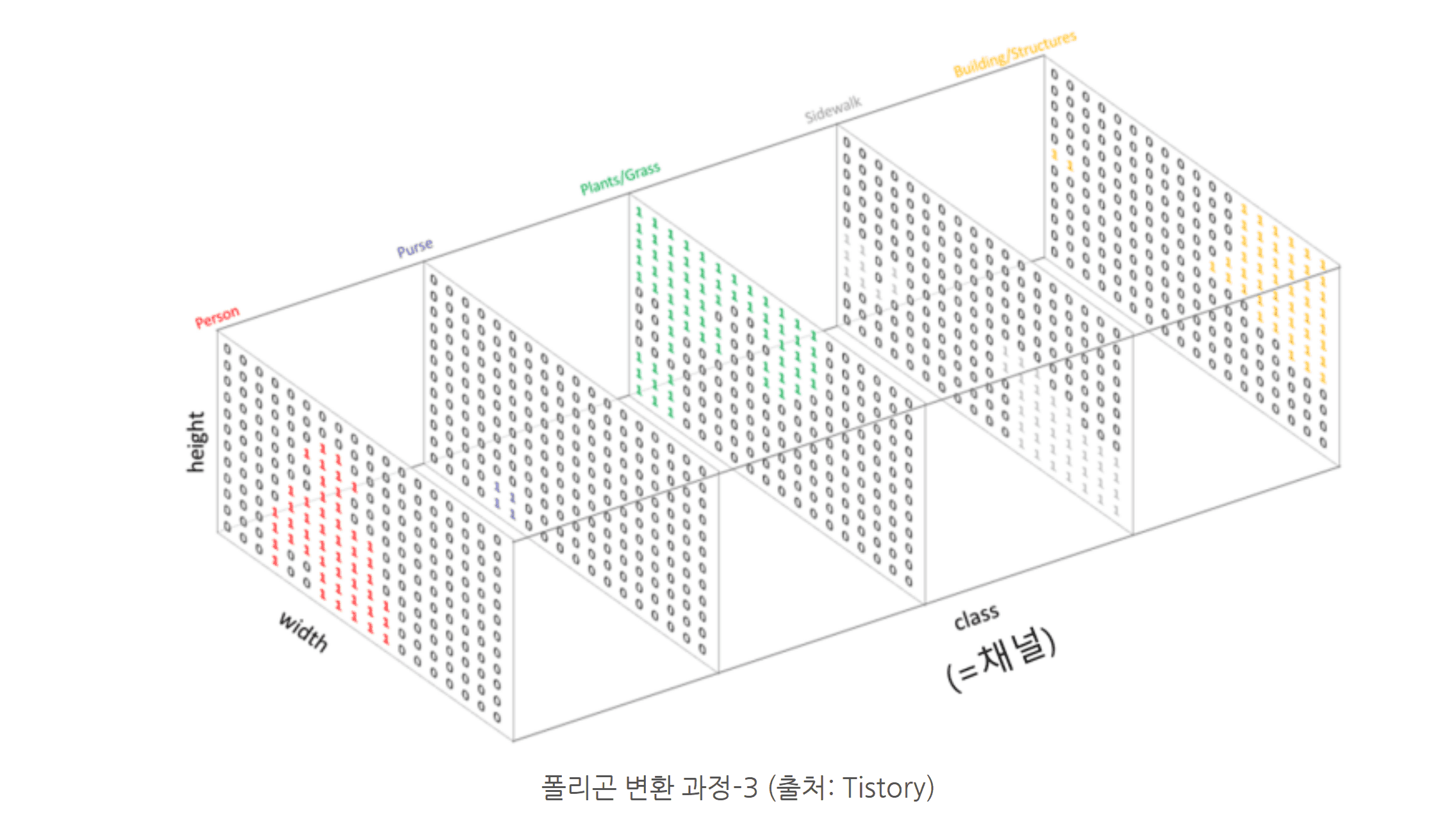
먼저, Segmentation은 이미지에서 물체마다 마스크를 씌우고 어떤 물체인지 예측하는 task입니다. 다음으로 GAN은 이미지 내 다양한 결함을 학습해 있을 법한 결함을 생성하며, 마지막으로 Anomaly Segmentation은 anomaly, 즉 이상이 있는 부분에 마스크를 씌웁니다. 이들 모델의 학습에는 탐지 대상이 담긴 마스크와 해당 자연어 태그가 필요합니다. 이때, 자연어 태그는 벡터 형태로 변환되지만, 이미지가 아닌 픽셀 단위로 벡터가 지정됩니다.

폴리곤 변환 과정-1 (출처: Tistory)
폴리곤 변환 과정-2 (출처: Tistory)
폴리곤 변환 과정-3 (출처: Tistory)
위의 과정을 통해 만들어진 폴리곤은 모델에 입력되기 전, 마스크 형태로 변환됩니다. 마스크는 각 폴리곤 내부 픽셀에 클래스를 부여한 것으로, 이미지의 모든 픽셀을 이미지로 간주해 각각 분류하는 것과 유사합니다. 따라서 Classification이나 Detection보다 훨씬 더 복잡하고 어려운 task라 할 수 있습니다.
한편으로는 Detection과 비슷하게, 이러한 task에서는 배경이 최대한 적게 들어가도록 폴리곤을 그렸는지에 따라 모델의 성능이 크게 달라지게 됩니다.
[2] Anomaly Classification
Anomaly Classification은 이미지 분류와 가장 유사한 task이지만, 정상 클래스에 대해서만 학습을 진행합니다. 본래 레이블이 필요 없는 방법이지만, 정상 클래스에 대한 학습을 한 후 성능을 평가하기 위해선 정상/비정상에 대한 레이블이 요구됩니다.
[3] Rotation
Rotation에서는 이미지가 원하는 각도에서 틀어진 정도를 1도 단위로 레이블링합니다. 이때, 이미지가 몇 도나 회전했는지, -180° < θ ≤ 180° 사이로 레이블링하게 됩니다.
데이터 수량과 모델 성능 간 관계
출처: velog
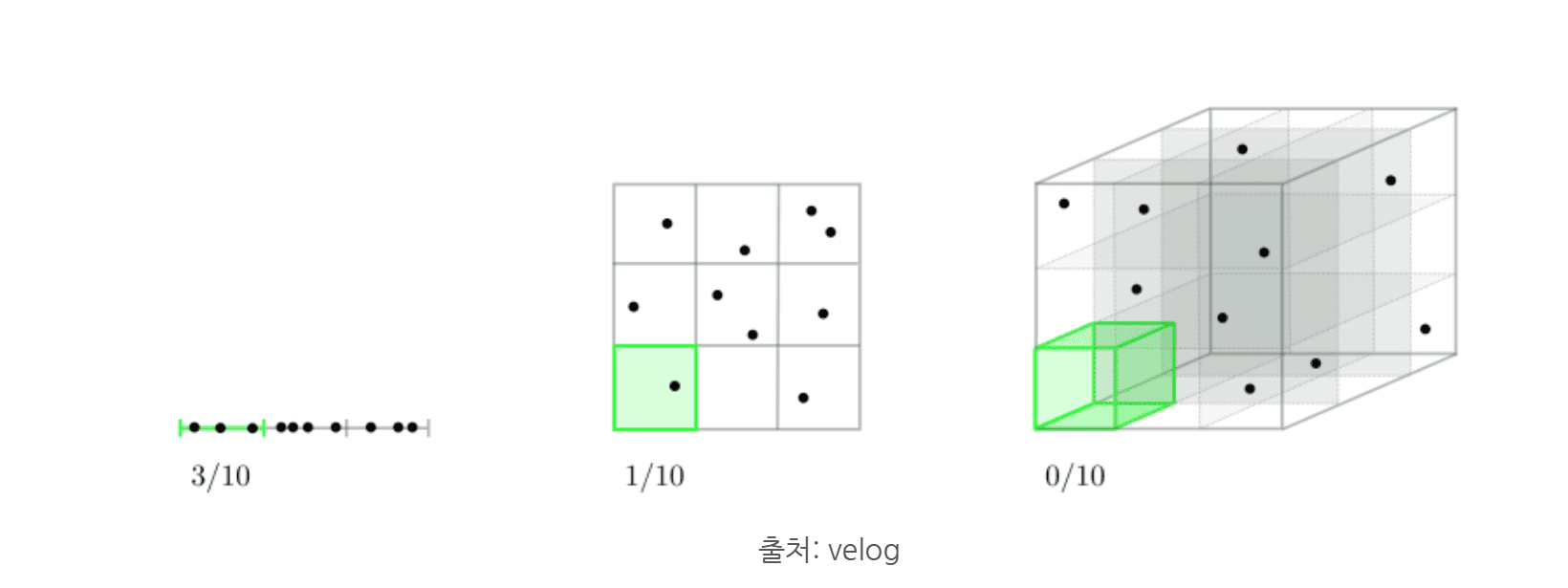
위의 이미지에서 알 수 있듯, 데이터의 차원이 높아질수록 같은 양의 데이터로는 관계를 파악하기 어려워지며, 이를 차원의 저주라고 합니다. 차원이 클수록 좋은 모델을 위해 필요한 데이터 양도 많아지며, 데이터가 부족하면 오버 피팅이 발생할 수 있습니다. 예를 들어, RGB 32x32 이미지는 3,072차원, 800x800 이미지는 1,920,000차원을 가지므로 고차원 이미지일수록 많은 데이터가 필요합니다. 그렇다면, 얼마나 많은 데이터가 있어야 하는 것일까요?
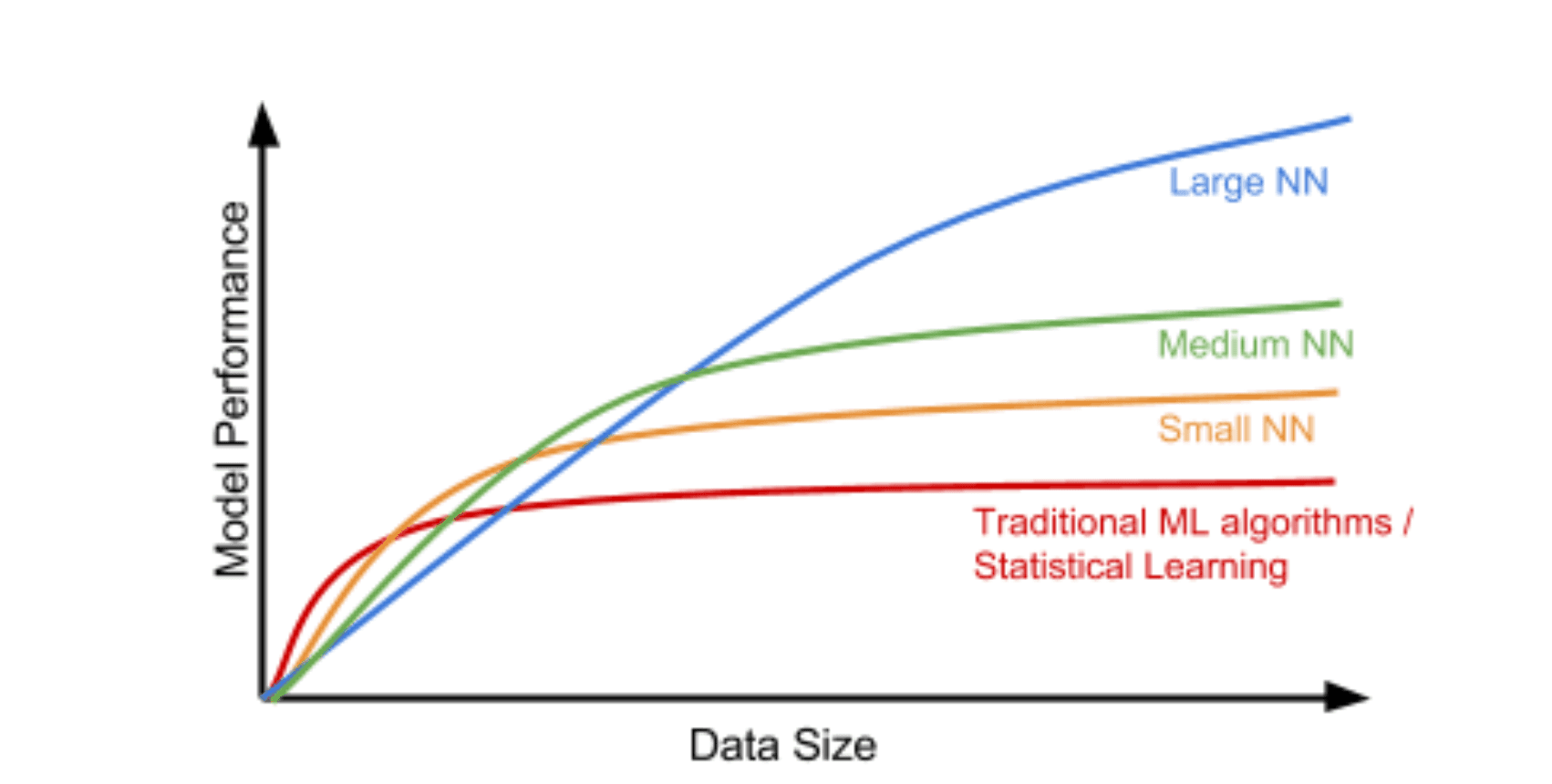
아쉽게도 확실한 기준은 없지만, 딥러닝에서는 데이터가 많을수록 성능이 좋아지는 경향이 있어, 가능한 한 많은 데이터를 확보하는 것이 좋습니다.
출처: github
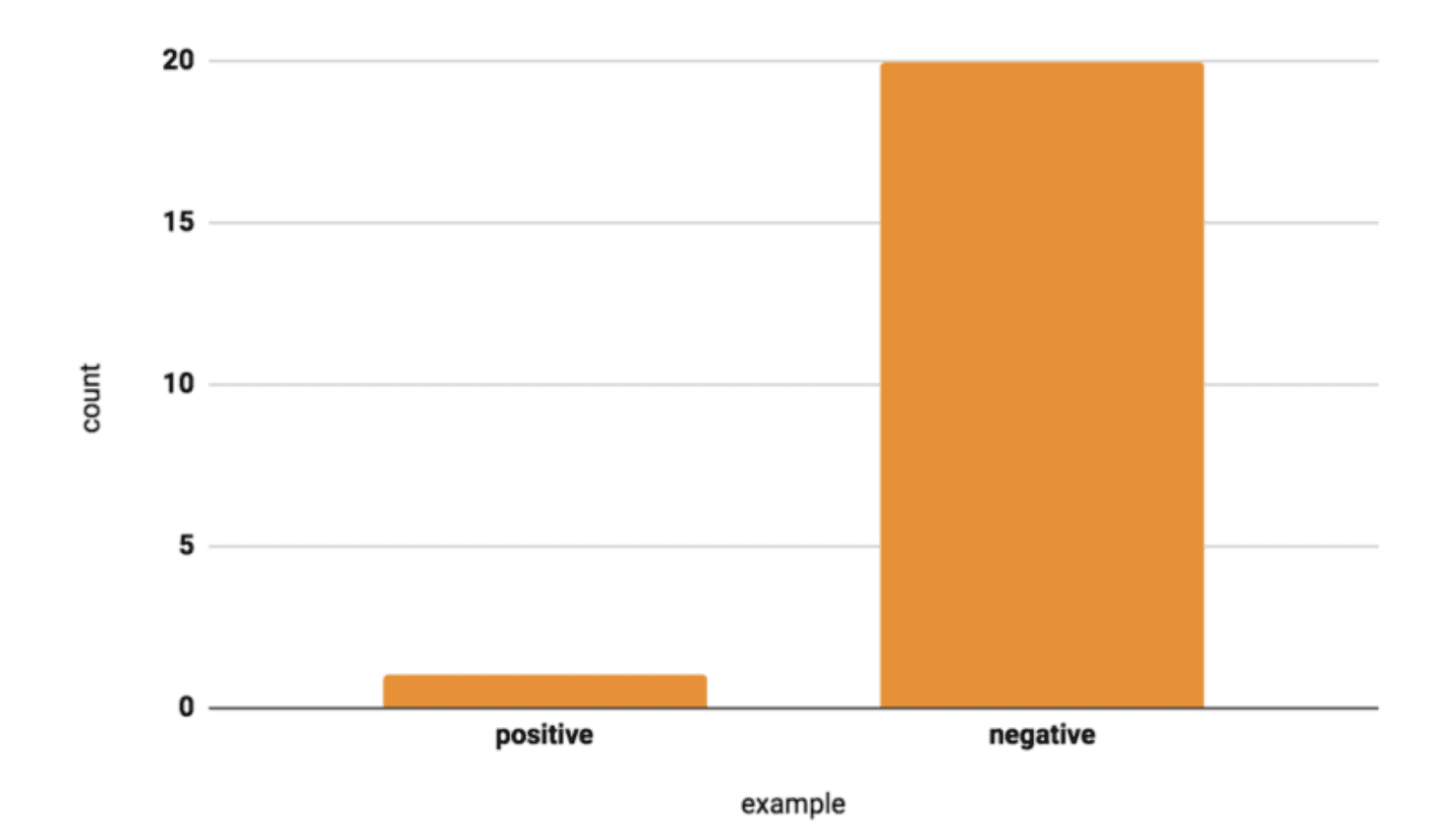
출처: Google for Developers
딥러닝에서는 데이터양뿐만 아니라 클래스 분포의 균형도 매우 중요합니다. 예를 들어, 결함 비율이 1%인 제품 데이터를 그대로 반영하면, 모델이 대부분을 정상으로만 예측해도 높은 성능 지표를 보일 수 있습니다. 하지만 실제 결함 비율이 달라질 경우(예: 평가 데이터 내 결함의 비율 증가) 예측이 매우 불안정해질 수 있습니다. 이는 모델이 제대로 학습되지 않았다는 신호이며, 클래스 불균형 문제를 의미합니다. 이를 방지하기 위해선 클래스 분포를 균형 있게 구성한 학습 데이터 셋이 필요합니다.

출처: MIT
하지만 간혹 딥러닝 모델이 물체를 잘못 예측하는 경우도 있습니다. 예를 들어, 위의 좌측 이미지는 소로 정확히 예측하는 반면, 우측 이미지는 ‘해변’으로 예측하기도 합니다. 이는 특정 이미지가 초점을 맞추는 대상이 무엇인지 쉽게 맞출 수 있는 사람에 반해 딥러닝 모델은 그러하기가 매우 어렵기 때문입니다. 특히 데이터 수가 적고 다양성이 부족할수록 이런 편향된 학습이 발생하기 쉬워집니다. 따라서 데이터를 만들 때는 이러한 편향을 주의해야 합니다.
마치며
이번 포스트에서는 저번 시간에 이어 추가적인 task 들과 함께 데이터 수량과 딥러닝 모델 간의 관계에 대해 더 깊이 살펴보았습니다. 무엇보다 딥러닝 모델의 성능을 극대화하려면 균형 잡힌 데이터로 방지하고, 정확히 레이블링하는 것이 필수적입니다. 다음 시간에는 이를 바탕으로 뉴로클의 딥러닝 기반 비전 검사 소프트웨어인 뉴로티의 여러 레이블링 도구들을 살펴보겠습니다.


