Neuro-Tech
[딥러닝101] 딥러닝 구조와 학습 원리 2편: 머신러닝 개념과 딥러닝 모델
들어가며
지난 시간에는 인공신경망의 등장과 함께 시작된 딥러닝의 역사, 그리고 이후 기술 발전을 이끈 주요 사건들을 살펴보았습니다. 이를 통해 딥러닝이 어떻게 발전해 왔는지 한층 더 깊이 있게 이해할 수 있었는데요.
오늘은 딥러닝의 상위 개념인 머신러닝과 딥러닝 모델에 대해 자세히 알아보도록 하겠습니다!
딥러닝의 상위 개념, '머신러닝'이란?
머신러닝과 딥러닝은 모두 데이터를 기반으로 학습하는 인공지능(AI) 기술이며, 딥러닝은 머신러닝의 하위 개념으로 분류됩니다.

머신러닝에서는 특징(feature)을 사람이 직접 정의하는 과정이 필요합니다. 예를 들어 고양이와 개를 구분하는 모델을 만들려면, "귀의 모양"이나 "털의 길이"처럼 어떤 특징이 중요한지를 사람이 먼저 설계해 줘야 합니다.
반면 딥러닝은 방대한 데이터를 통해 유용한 특징을 스스로 학습합니다. 사람이 일일이 특징을 정의하지 않아도 모델이 데이터에서 중요한 패턴을 찾아내는 것이죠.
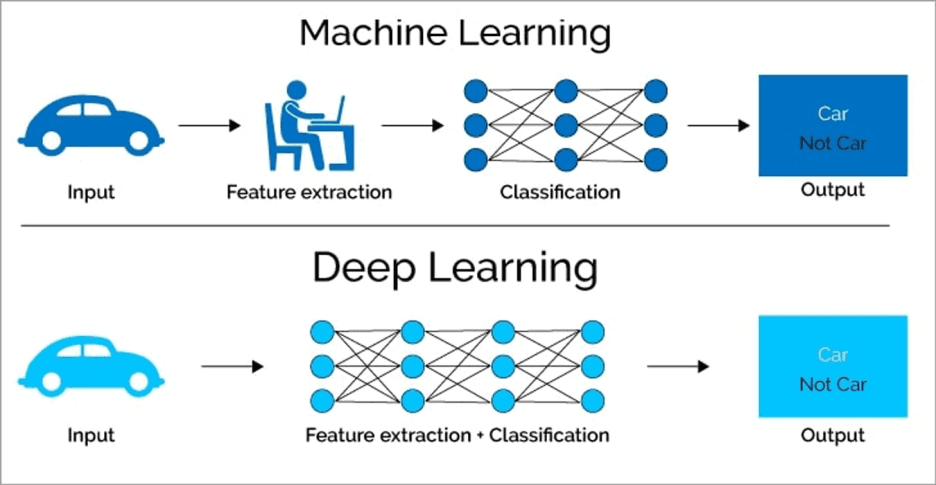
머신러닝은 비교적 적은 데이터와 계산 자원으로도 좋은 성능을 낼 수 있으며, 모델 해석이 쉽다는 장점이 있습니다. 하지만 복잡한 문제를 해결할 때는 사람이 중요한 특징을 잘 설계해 주는 것이 필수적입니다.
딥러닝은 사람이 특징을 일일이 설계하지 않아도, 대규모 데이터로 복잡한 패턴을 스스로 학습할 수 있습니다. 덕분에 이미지 인식, 음성 인식, 자연어 처리 등 다양한 분야에서 뛰어난 성과를 보여주고 있죠. 그러나 무수한 데이터와 계산 자원이 필요하며, 학습 과정이 블랙박스처럼 작동해 해석이 어렵고 시간과 비용이 많이 든다는 단점도 존재합니다.
'딥러닝 모델'이란? - 구조와 학습 방식 톺아보기
딥러닝에서 모델은 입력을 받아 출력을 생성하는 함수라고 볼 수 있습니다. 이 함수는 복잡한 형태일 수도 있지만, 기본적으로는 주어진 입력을 특정한 규칙에 따라 변환해 우리가 원하는 출력을 만들어냅니다.

그렇다면, 모델이 '학습한다'라는 것은 무슨 뜻일까요? 이는 모델 내부에 존재하는 수많은 숫자들, 즉 파라미터(parameter)가 학습 과정을 통해 조정됨을 의미합니다. 학습이 진행될수록 이 숫자들은 입력과 출력 간의 관계를 더 정확히 반영하게 되며, 모델은 새로운 입력에도 보다 정확한 예측을 할 수 있게 됩니다.
모델의 너비(width)와 깊이(depth)는 모델 복잡도를 결정하는 핵심 요소입니다. 너비는 각 레이어의 노드 수, 깊이는 레이어의 수를 의미하며, 값이 커질수록 더 많은 정보를 처리하고 복잡한 패턴을 학습할 수 있습니다. 그러나, 문제의 난이도에 비해 모델이 지나치게 크면 오히려 성능이 저하되거나 학습이 비효율적일 수 있습니다. 따라서 모델 크기는 문제의 난이도와 데이터의 특성에 맞춰 신중하게 조절해야 하죠.
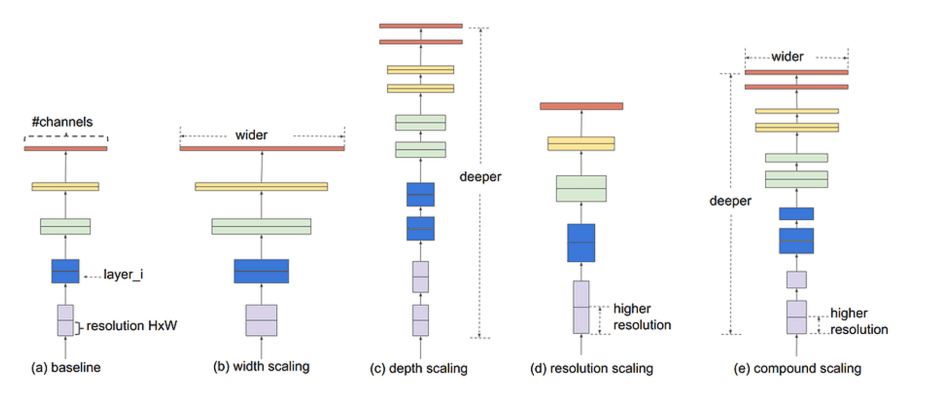
모델의 크기를 나타내는 대표적인 지표로는 파라미터 수와 FLOPS, 그리고 지연 시간이 있습니다.
먼저, 파라미터 수는 모델 내부의 가중치나 편향과 같이 조정 가능한 숫자의 총개수를 뜻합니다. 일반적으로 파라미터 수가 많을수록 모델은 더 많은 정보를 저장하고 복잡한 패턴을 학습할 수 있습니다. 하지만 데이터가 부족하거나 문제의 복잡도에 비해 그 수가 지나치게 많을 경우, 오히려 오버 피팅(overfitting)을 유발할 수 있습니다.
다음으로 FLOPS (Floating Point Operations Per Second)는 모델이 처리하는 부동소수점 연산의 총량을 나타내며, 모델의 계산량과 직접적으로 연결됩니다. FLOPS가 높을수록 연산 비용이 많이 들지만, 그만큼 복잡한 패턴을 더욱 세밀하게 처리할 수 있습니다.

마지막으로 지연 시간은 입력부터 출력까지 걸리는 시간을 의미하며, 특히 실시간 응답이 중요한 시스템에서 중요한 모델 크기 지표로 작용합니다.
유형별로 알아보는 딥러닝 모델
닝이 발전하며 다양한 형태의 모델도 등장하게 되었는데요. 지금부터는 대표적인 딥러닝 모델인 CNN, RNN, 그리고 Transformer의 특징과 차이점에 대해 간략히 살펴보도록 하겠습니다.
먼저, CNN (Convolutional Neural Network)은 주로 이미지 처리에 특화된 신경망 구조로, 입력 이미지의 지역적인 특징을 추출하는 데 효과적입니다. 합성곱(Convolution) 연산을 통해 공간 구조를 보존하면서 학습하며, '공간적으로 가까운 정보는 관련이 높다'는 인덕티브 바이어스(Inductive Bias)를 기반으로 작동합니다. 덕분에 적은 데이터로도 뛰어난 성능을 발휘하고, 복잡한 이미지나 패턴 인식에 널리 사용됩니다.
다음으로 RNN (Recurrent Neural Network)은 순차적 데이터(예: 문장, 시계열)를 처리하는 데 적합한 모델로, 데이터의 입력 순서를 반영해 과거 정보를 기억하며 다음 출력을 예측합니다. 하지만, 시간이 길어질수록 과거 정보를 잊는 장기 의존성 문제와 기울기 소실 문제가 발생하기 쉽습니다. 이런 한계로 최근에는 Transformer가 RNN을 대체하는 추세로 변화하고 있습니다.
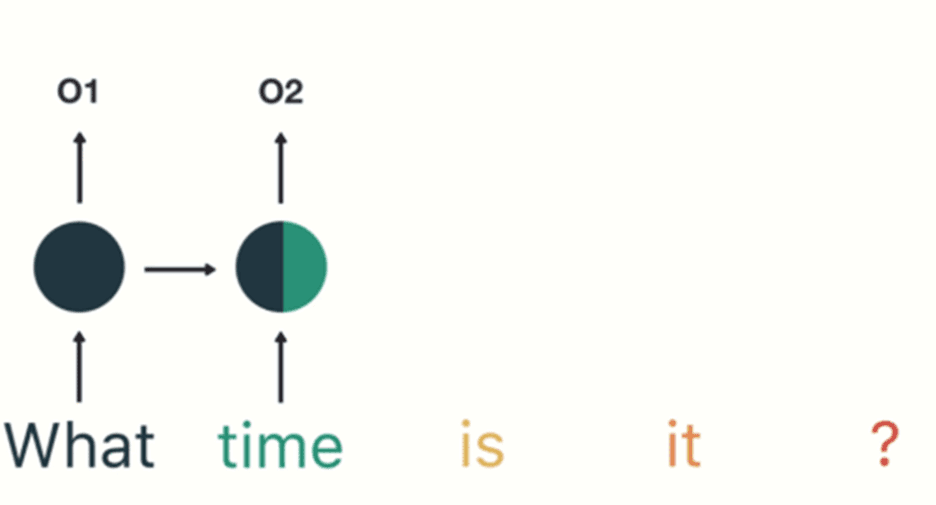
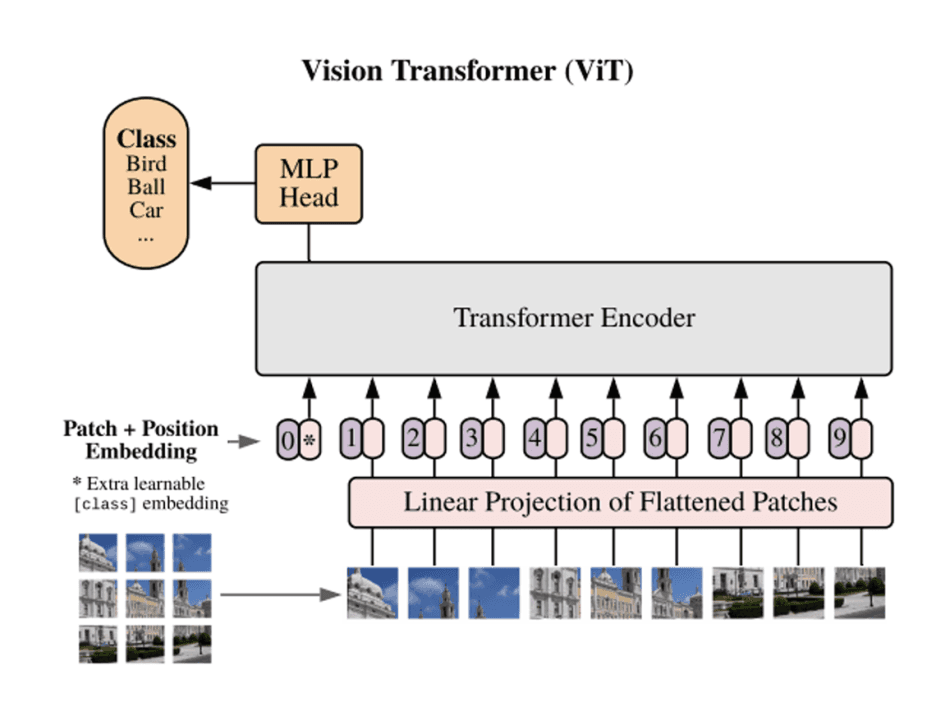
마지막으로 Transformer는 입력 데이터를 일정한 크기의 작은 조각 단위, 즉 패치(Patch)로 나누고, 각 패치 간 관계를 학습하는 모델입니다. 따라서 병렬 처리에 강하고, 데이터와 연산량이 많을수록 성능이 더 좋아지는 scale-up 친화적 구조를 가지고 있습니다. 그러나 높은 성능만큼 학습과 추론에 많은 자원을 필요로 한다는 단점이 있습니다.
마치며
이번 시간에는 머신 러닝과 딥러닝의 개념부터 다양한 딥러닝 모델들을 살펴보았습니다. 딥러닝 모델은 각기 다른 방식으로 데이터를 해석하고 처리하면서, 학습을 통해 점점 더 정교한 결과를 만들어냅니다. 이 글이 딥러닝에 대한 이해의 폭을 넓히는 데 도움이 되었기를 바랍니다.
다음 편에서는 이를 바탕으로 딥러닝 모델의 학습 원리에 대해 자세히 알아보겠습니다.


