Neuro-Tech
[딥러닝101] 딥러닝 구조와 학습 원리 3편 : 모델 학습의 의미와 손실 함수
들어가며
지난 시간에는 딥러닝의 상위 개념인 머신러닝과 다양한 딥러닝 모델을 살펴보았습니다. 모델마다 데이터 처리 방식은 다르지만, 학습을 통해 점점 더 정확한 결과를 낸다는 공통점이 있었는데요.
오늘은 이를 바탕으로 모델 학습의 개념과, 학습이 잘 이뤄지고 있는지를 평가하는 방법에 대해 알아보도록 하겠습니다!
딥러닝에서 모델 ‘학습'이란?
지난 시간에서 딥러닝 모델은 하기 이미지와 같이 입력을 받아 출력을 생성하는 함수임을 알 수 있었습니다.
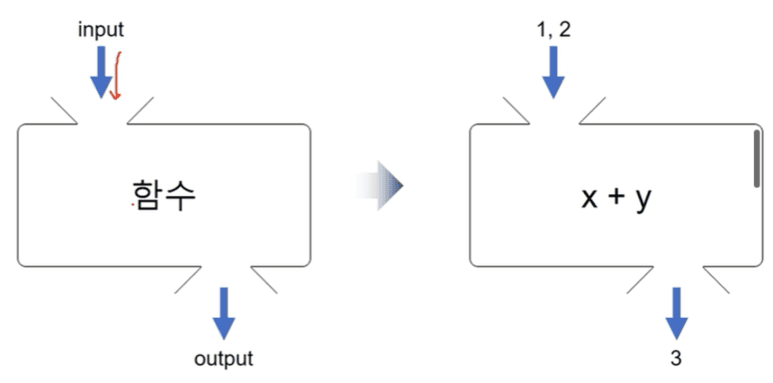
따라서 좋은 모델을 만들기 위해서는 주어진 입력에 대해 올바른 출력을 생성하도록 학습시켜야 하는데요. 학습 방법에는 여러 가지가 있지만, 결국 모델 학습은 '모델이 생성한 출력(예측한 값)이 실제 나와야하는 출력(실제 값)과 최대한 일치하도록 만드는 과정'이라고 할 수 있습니다.
모델 학습, '손실 함수'로 평가한다
그럼 어떻게 모델이 예측한 값과 실제 나와야 하는 값이 일치하도록 만들 수 있을까요?
모델 학습의 핵심은 예측이 맞았는지 틀렸는지, 그리고 틀렸다면 얼마나 차이가 나는지를 측정하는 데 있습니다. 이 차이를 수치로 나타낸 함수가 바로 '손실 함수(Loss Function)'입니다.
이제 대표적인 두 가지 손실 함수들을 함께 살펴보도록 하겠습니다.
평균 제곱 오차 (MSE, Mean Squared Error Loss)
평균 제곱 오차(이하 MSE)는 그 이름에서도 알 수 있듯, 오차(Error)를 제곱한 값의 평균입니다.
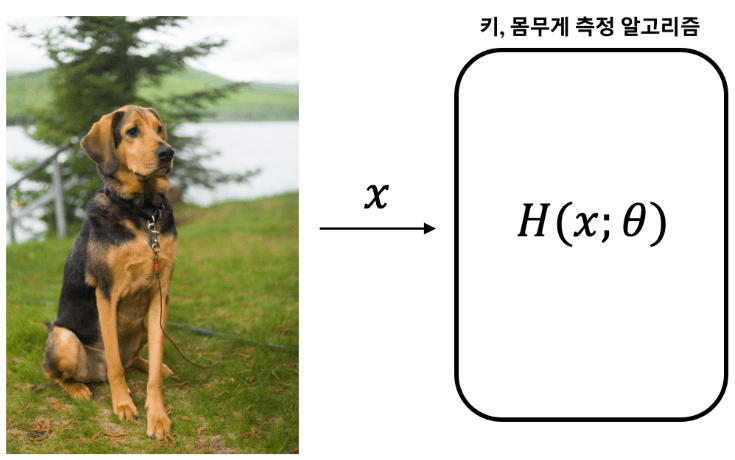
출처: Tistory
예를 들어, 위 강아지 사진에서 실제 키(40.5cm)와 몸무게(21.3kg)를 측정하는 모델이 있다고 가정해 보겠습니다.
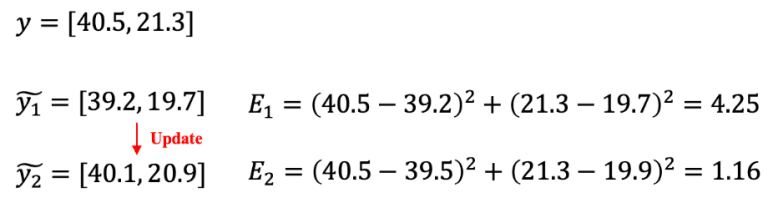
이때 모델이 키 39.2cm, 몸무게 19.7kg으로 예측하면 MSE Loss는 4.25가 되고, 학습 후 키 40.1cm, 몸무게 20.9kg으로 예측하면 MSE Loss는 1.16으로 감소하게 됩니다.
한편 평균 절대 오차(MAE, Mean Absolute Error)는 MSE에서 제곱만 절대값으로 바꾼 오차입니다.
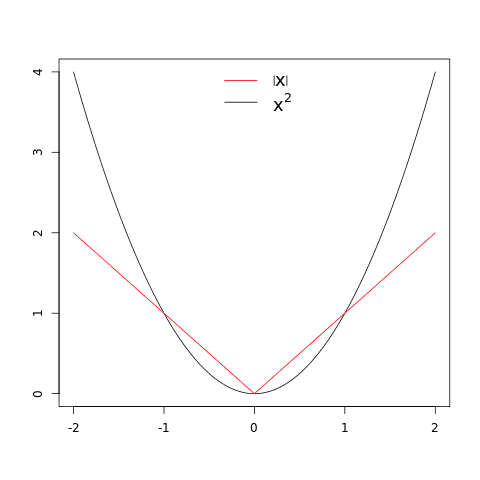
x² 그래프와 |x| 그래프를 보면 MSE Loss가 MAE Loss보다 틀린 값이 클수록 더 크게 증가하는 것을 알 수 있는데요. 따라서 MSE Loss는 MAE Loss보다 이상치에 더 민감하다고 할 수 있습니다.
Cross Entropy Loss
Cross Entropy Loss는 Classification, Segmentation, Object Detection 등의 딥러닝 모델에서 기본적으로 사용되는 손실 함수입니다. 이를 이해하려면 정보 이론에 대한 간략한 이해가 필요합니다.
모든 정보는 ‘정보량’으로 측정할 수 있습니다. 정보량은 ‘예’ 또는 ‘아니오’를 질문해야하는 개수라고 볼 수 있죠. 예를 들어, 동전 5개의 앞면(0)과 뒷면(1)을 구분하려면 5번의 질문이 필요하며, 이때 가능한 경우의 수는 25=32이므로, 정보량은 다음과 같이 표현할 수 있습니다.
앞서 정보량에서 말한 ‘가능한 경우의 수’의 역수는 ‘어떤 상황이 일어날 확률’이 됩니다. 일례로, 동전 5개를 던져 앞뒤뒤앞뒤(01101)가 나올 확률은 1/32입니다. 따라서 위 수식은 다음과 같이 전개할 수 있습니다.
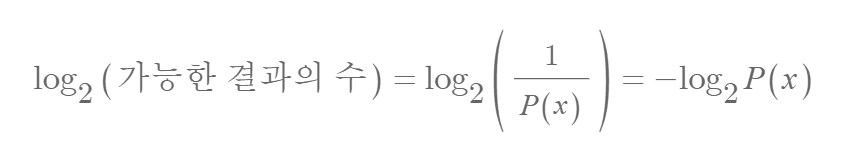
엔트로피(Entropy)는 어떤 상황의 불확실성, 즉 정보량을 정량화한 단위입니다. 앞서 예시로 든 동전 5개를 던지는 경우의 불확실성은 다음과 같이 계산할 수 있습니다.
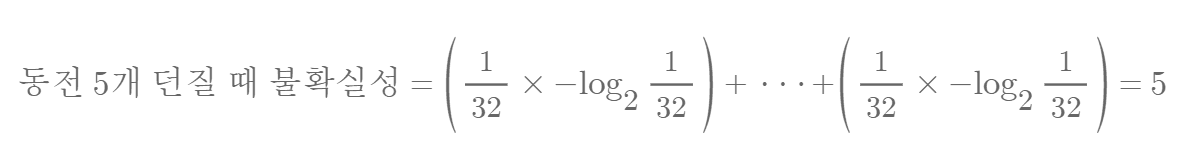
이를 통해 엔트로피(==H) 수식을 알 수 있습니다. ( P(xi) == pi )
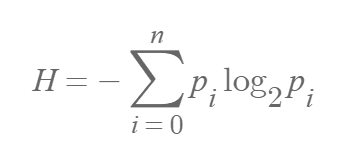
위 예시처럼 모든 경우의 수와 확률, 즉 확률 분포를 알고 있을 때만 엔트로피를 정확히 계산할 수 있습니다. 이때 동일한 상황에 대한 엔트로피는 변하지 않습니다. 하지만 모델 학습에서는 실제 정답의 확률 분포와 모델이 예측하는 확률 분포가 다릅니다.
이렇듯 서로 다른 두 확률 분포가 있을 때 사용하는 것이 바로 Cross Entropy (==H (p,q))입니다. 실제 확률 분포 p에 대해 확률 분포 q를 사용할 때의 불확실성은 다음과 같이 표현됩니다.
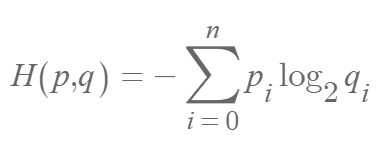
정답과 예측 확률을 직접 비교할 수 있기 때문에, Cross Entropy는 MSE, MAE Loss처럼 연속형 데이터(예: 키, 몸무게)가 아닌 범주형 데이터(예: 동물 종류)에 사용됩니다.
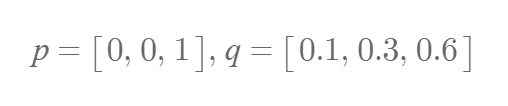
위와 같이 p와 q가 있을 때 Cross Entropy는 아래와 같이 계산됩니다.
이처럼 Cross Entropy를 사용하려면 모델의 레이블을 문자 대신 [0,1,0,0]과 같은 원-핫 인코딩(One-hot encoding) 형태로 변환해줘야 합니다. 원핫인코딩(One-hot encoding)은 범주형 데이터를 컴퓨터가 이해할 수 있는 숫자 형태로 변환하는 방법으로, 각 클래스를 해당 위치만 1이고 나머지는 0인 벡터로 표현합니다.
학습이 되어 q가 위와 같이 변화했다면 아래와 같이 계산됩니다.
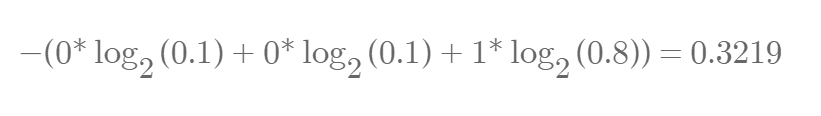
Cross Entropy는 qi가 pi에 가까워질수록 값이 작아지는 특성이 있어, 딥러닝에서 현재 널리 사용되고 있습니다.
마치며
이번 시간에는 모델 학습의 의미와 함께 학습 성과를 평가하는 손실 함수에 대해 살펴보았습니다. 궁극적으로 모델 학습은 모델의 예측값과 실제값의 차이를 최소화하는 데 주안점이 있으며, 이를 위해 손실함수를 활용하게 되죠.
다음 편에서는 손실 함수의 최솟값을 찾아내는 '경사 하강법'에 대해 자세히 알아보겠습니다.


