Neuro-Tech
[Deep Learning 101] Deep Learning Architecture and Training Principles (Part 3): The Meaning of Model Training and Loss Functions
A brief overview of the meaning of model training and the loss function.
Introduction
In the previous article, we explored machine learning, a higher-level concept of deep learning, and various deep learning models. Although each model processes data differently, they all share the common characteristic of producing increasingly accurate results through training.
In this article, we will build on this and take a look at the concept of model training and how to evaluate whether training is being performed effectively.
What Does “Model Training” Mean in Deep Learning?
In the previous article, we learned that a deep learning model is a function that takes an input and generates an output, as shown in the image below.
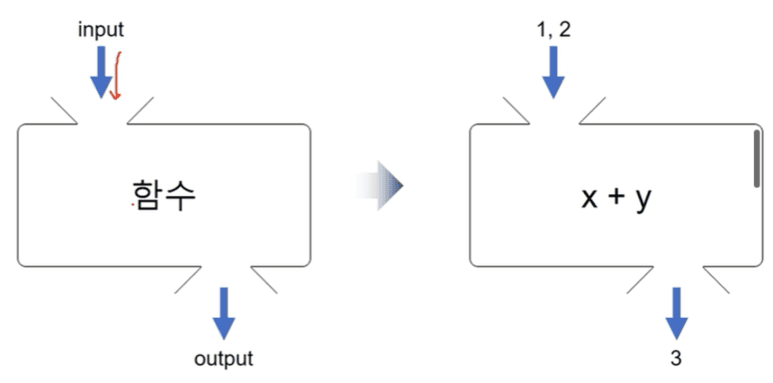
Therefore, in order to build a good model, it must be trained to produce the correct output for a given input. While there are various training methods, model training can ultimately be defined as the process of making the model’s output (predicted value) match the actual output (ground truth) as closely as possible.
Evaluating Model Training with a “Loss Function”
Then how can we make the model’s predictions match the actual values?
The core of model training lies in measuring whether the prediction is correct and, if not, how far it deviates from the actual value. The function that expresses this difference numerically is called the loss function.
Now, let’s take a look at two representative loss functions.
Mean Squared Error (MSE, Mean Squared Error Loss)
As the name suggests, Mean Squared Error (MSE) is the average of the squared errors.
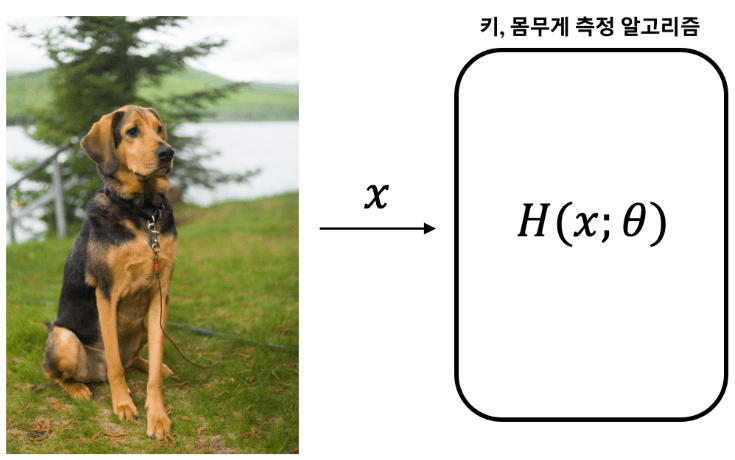
Source: Tistory
For example, suppose there is a model that measures the actual height (40.5 cm) and weight (21.3 kg) of the dog shown in the image above.
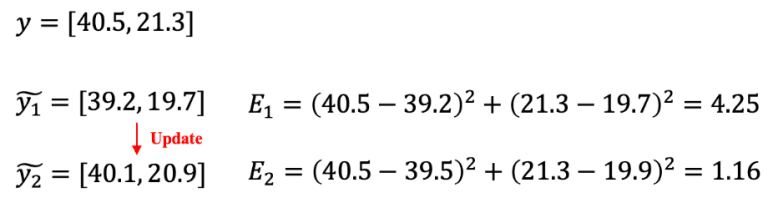
If the model predicts a height of 39.2 cm and a weight of 19.7 kg, the MSE loss becomes 4.25. After training, if it predicts a height of 40.1 cm and a weight of 20.9 kg, the MSE loss decreases to 1.16.
On the other hand, Mean Absolute Error (MAE) is similar to MSE but uses the absolute value instead of squaring the error.
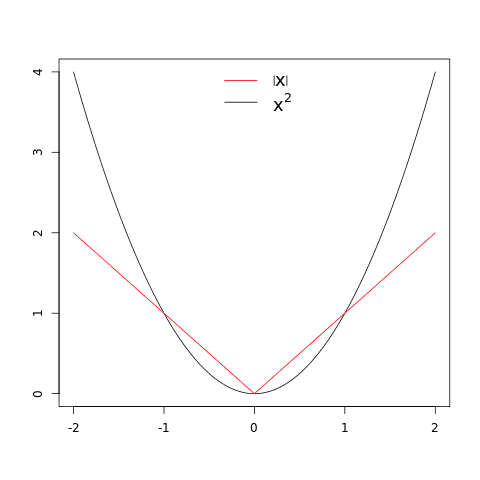
From the graphs of x² and |x|, we can see that MSE loss increases more rapidly than MAE loss as the error becomes larger. Therefore, MSE loss is more sensitive to outliers than MAE loss.
Cross Entropy Loss
Cross Entropy Loss is a loss function commonly used in deep learning models such as classification, segmentation, and object detection. To understand it, a basic understanding of information theory is required.
All information can be measured in terms of “information content.” Information content can be interpreted as the number of “yes” or “no” questions required.
For example, to distinguish the outcomes of five coin tosses (heads = 0, tails = 1), five questions are required. Since the number of possible cases is 2⁵ = 32, the information content can be expressed as follows.
The inverse of the “number of possible cases” corresponds to the probability of a certain event occurring. For example, the probability of obtaining a specific sequence such as 01101 when tossing five coins is 1/32. Therefore, the above expression can be rewritten as follows.
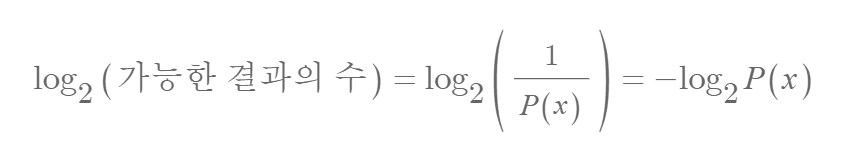
Entropy is a measure that quantifies the uncertainty of a situation, or the amount of information. The uncertainty of the five coin toss example can be calculated as follows.
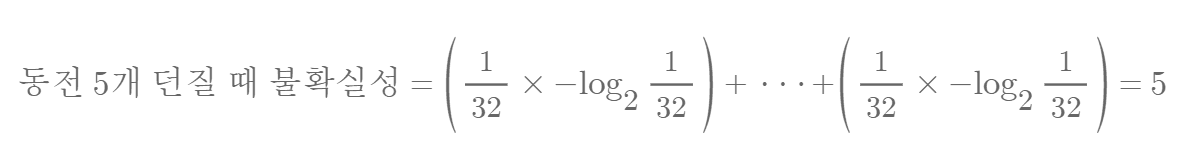
From this, we can derive the entropy (H) formula. (P(xi) = pi)
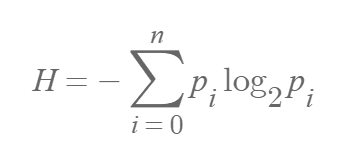
As shown in the example above, entropy can only be calculated accurately when all possible cases and their probabilities, that is, the probability distribution, are known. In this case, the entropy for the same situation does not change. However, in model training, the probability distribution of the ground truth and the probability distribution predicted by the model are different.
In such cases where two different probability distributions exist, Cross Entropy (H(p, q)) is used. The uncertainty when using probability distribution q instead of the true distribution p can be expressed as follows.
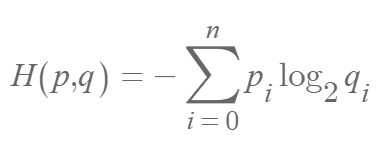
Since Cross Entropy directly compares the ground truth and predicted probabilities, it is used for categorical data (e.g., animal classes), unlike MSE or MAE, which are used for continuous data (e.g., height, weight).
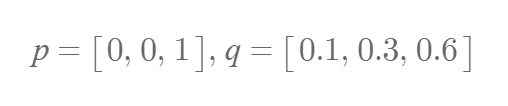
When p and q are given as above, Cross Entropy is calculated as follows.
To use Cross Entropy, the model labels must be converted into a one-hot encoding format such as [0, 1, 0, 0] instead of text labels. One-hot encoding is a method of converting categorical data into a numerical format that computers can understand, where each class is represented as a vector with a value of 1 at the corresponding index and 0 elsewhere.
If training progresses and q changes as shown above, it is calculated as follows.
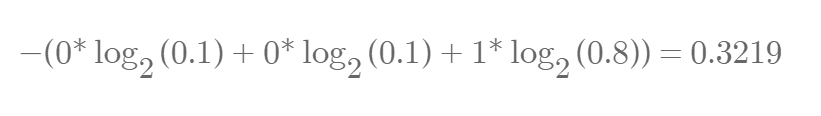
Cross Entropy has the characteristic that its value decreases as qi approaches pi, which is why it is widely used in deep learning.
Conclusion
In this article, we explored the concept of model training and the loss functions used to evaluate training performance. Ultimately, model training focuses on minimizing the difference between predicted values and actual values, and loss functions are used for this purpose.
In the next article, we will take a closer look at “gradient descent,” which is used to find the minimum value of the loss function.


