Neuro-Tech
[Deep Learning 101] Understanding Deep Learning Through Images (Part 4): Labeling and Data for Model Performance
Introduction
In the previous article, we looked at the labeling process required for training deep learning models and the tasks to which it is applied. In addition to the tasks we covered earlier—such as classification, object detection, and OCR—there are various other types of tasks. In this article, we will explore other types of tasks and examine the relationship between data quantity and deep learning models.
Dive into Tasks: What Else Is There?
In this section, we will look at five representative tasks: segmentation, GAN, anomaly segmentation, anomaly classification, and rotation. Although segmentation, GAN, and anomaly segmentation serve very different purposes, they can be explained together from a labeling perspective because they share the same labeling approach.
1. Segmentation/GAN/Anomaly Segmentation
First, segmentation is a task that applies masks to objects in an image and predicts what each object is. Next, GAN learns various defects in images and generates plausible defects, and anomaly segmentation applies masks to anomalous regions. Training these models requires masks that contain the target objects along with corresponding natural language tags. These tags are converted into vector form, but unlike image-level representations, vectors are assigned at the pixel level.

Polygon conversion process-1 (Source: Tistory)
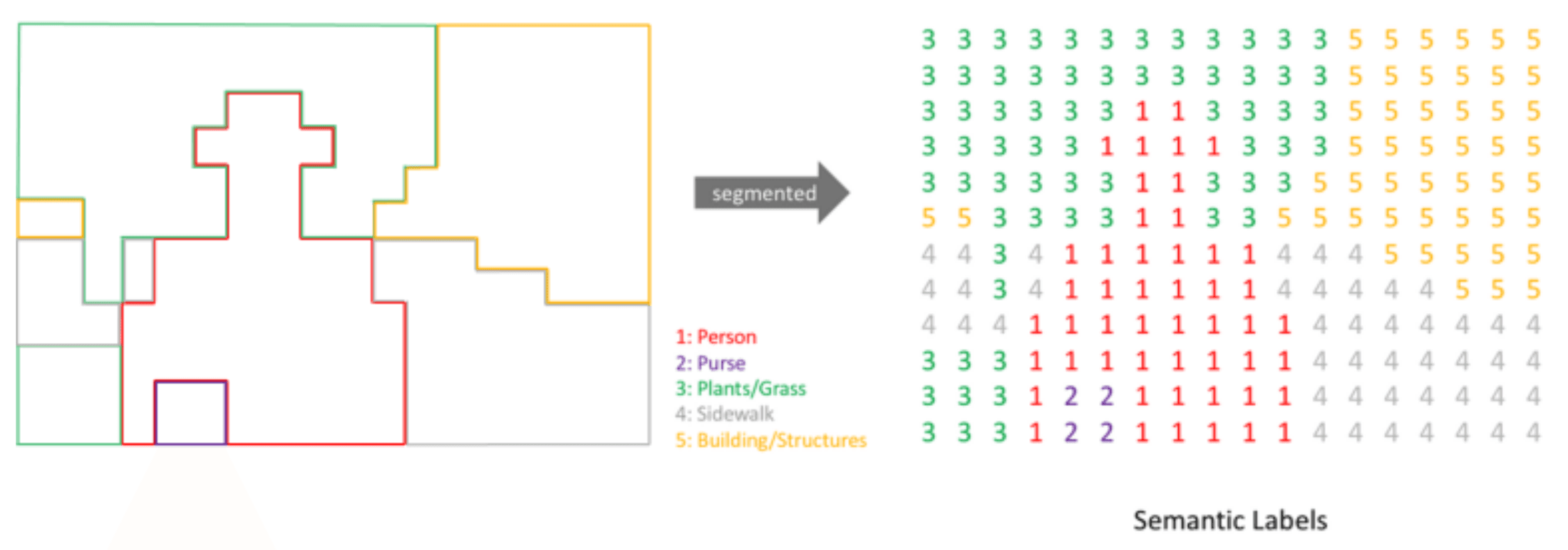
Polygon conversion process-2 (Source: Tistory)
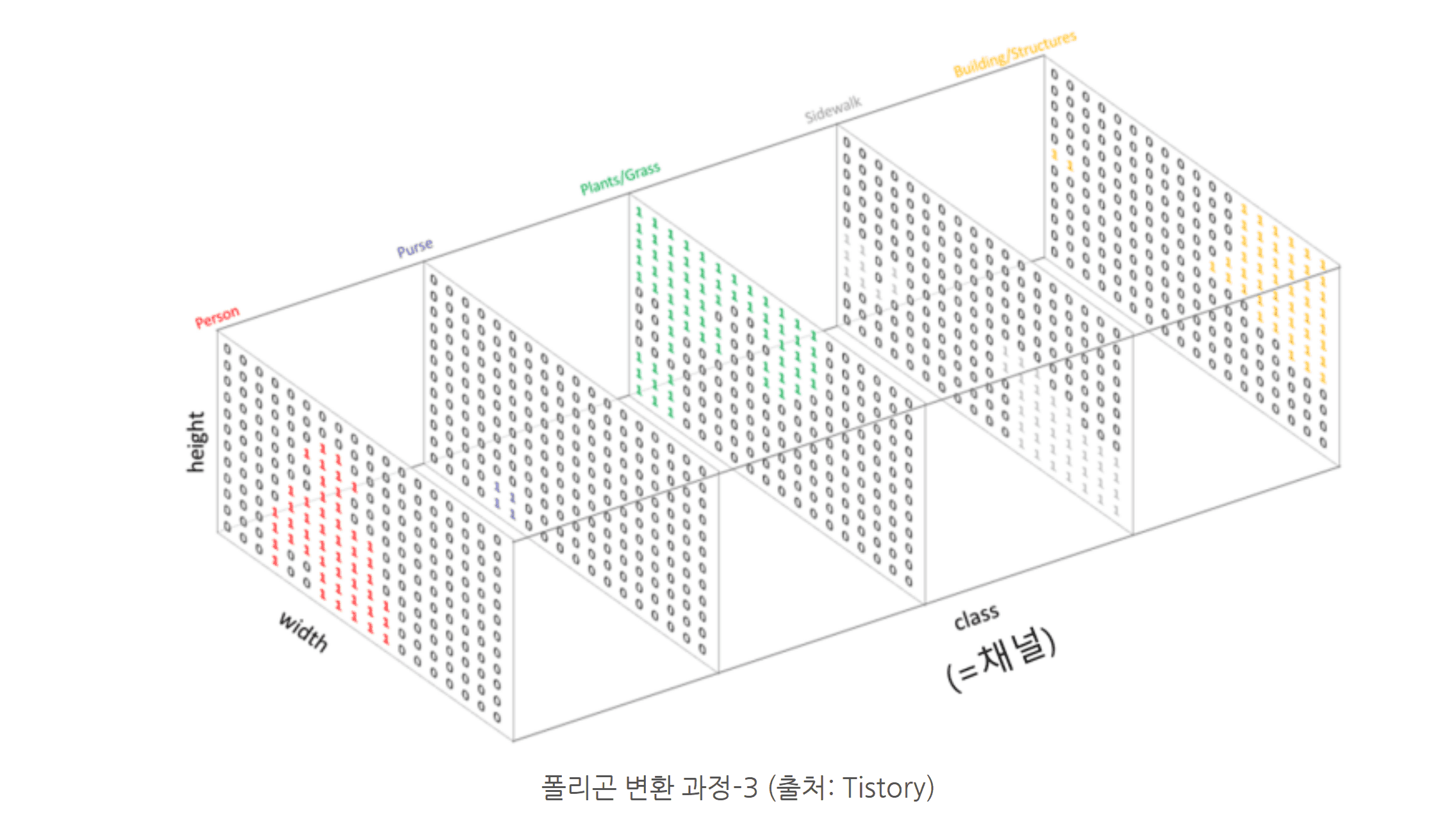
Polygon conversion process-3 (Source: Tistory)
The polygons created through this process are converted into mask form before being input into the model. A mask assigns a class to each pixel inside the polygon, which is similar to treating every pixel in the image as an individual classification target. Therefore, this task is much more complex and difficult than classification or detection.
Similar to detection, the performance of these tasks is greatly affected by how well the polygons are drawn to minimize background inclusion.
2. Anomaly Classification
Anomaly Classification is the most similar to standard image classification, but it is typically trained using only normal (non-defective) samples. While labeling is not strictly required during training, labels for both normal and abnormal classes are necessary for proper evaluation.
3. Rotation
In rotation estimation, the task is to predict the rotation angle of an image. Each image is labeled with a rotation value in degrees, typically within the range of -180° < θ ≤ 180°, with fine-grained resolution (e.g., 1-degree increments).
Data Quantity and Model Performance
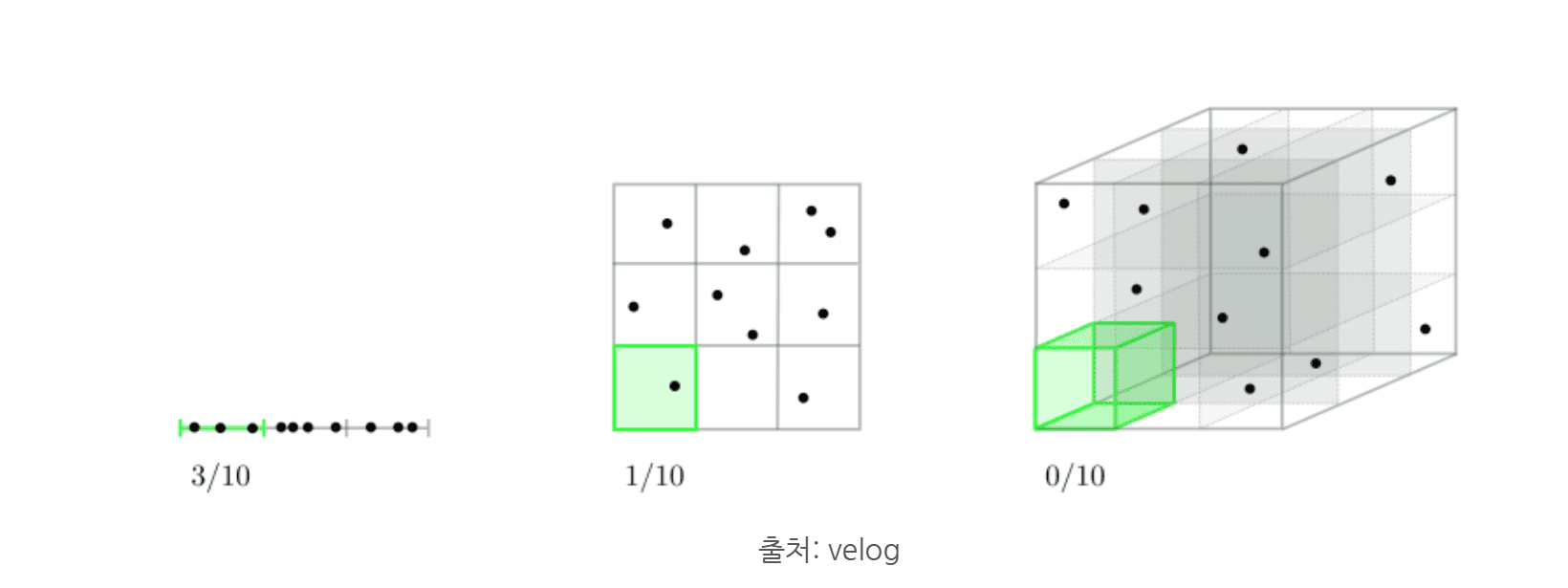
Source: velog
As shown above, as the dimensionality of data increases, it becomes more difficult to identify relationships with the same amount of data. This is referred to as the curse of dimensionality. As dimensionality increases, more data is required to build a good model, and if data is insufficient, overfitting may occur.
For example, a 32×32 RGB image has 3,072 dimensions, while an 800×800 image has 1,920,000 dimensions. Therefore, higher-dimensional images require more data.
There is no clear standard for how much data is needed, but in deep learning, performance generally improves as the amount of data increases. Therefore, it is recommended to secure as much data as possible.
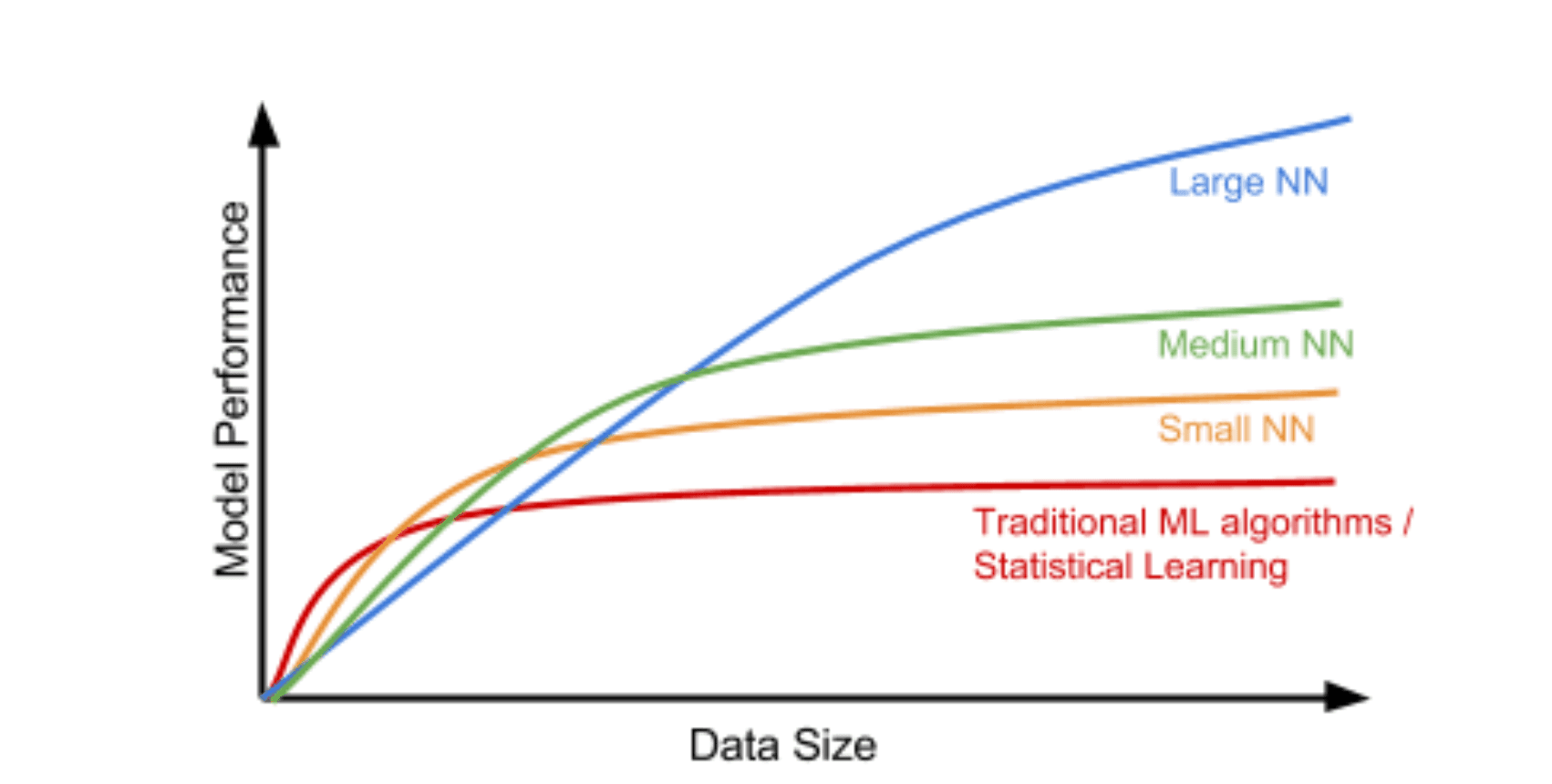
Source: github
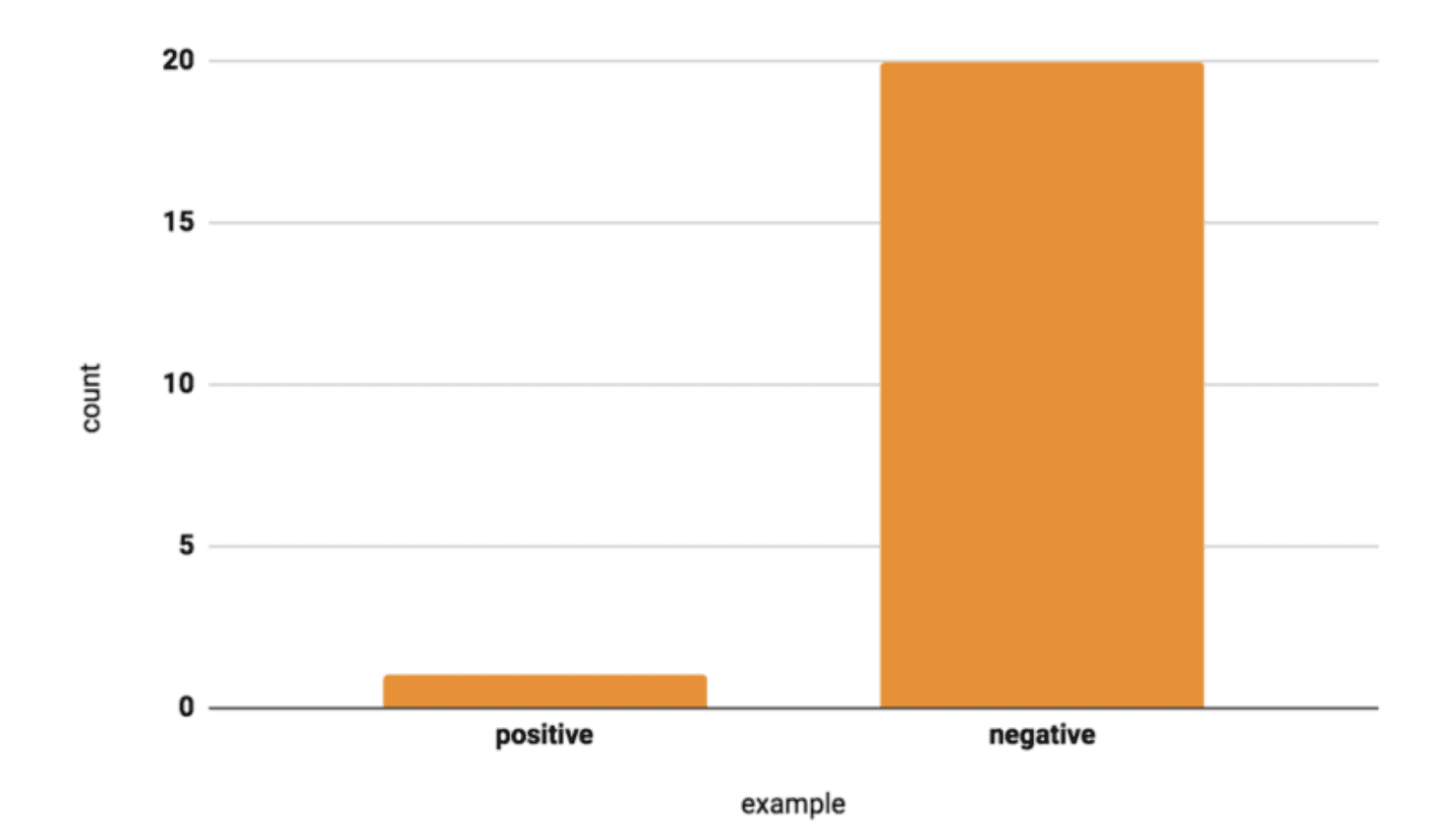
Source: Google for Developers
In deep learning, not only the amount of data but also the balance of class distribution is very important.
For example, if a dataset reflects a defect rate of 1%, a model may achieve high performance metrics by predicting most samples as normal. However, if the defect ratio changes (e.g., an increased proportion of defects in evaluation data), predictions can become highly unstable. This indicates that the model has not been properly trained and reflects a class imbalance problem. To prevent this, a training dataset with a balanced class distribution is required.

Source: MIT
However, deep learning models may sometimes make incorrect predictions. For example, while one image may be correctly predicted as a cow, another image may be predicted as a “beach.” Unlike humans, who can easily identify the main subject of an image, deep learning models find this very difficult. This type of biased learning is more likely to occur when the amount of data is small and lacks diversity. Therefore, such bias should be carefully considered when creating data.
Conclusion
In this post, we explored additional tasks along with the relationship between data quantity and deep learning models. Above all, to maximize the performance of deep learning models, it is essential to prevent issues with balanced data and to perform accurate labeling.
In the next article, we will look at various labeling tools in Neurocle’s deep learning-based vision inspection software, Neuro-T.


